Linear vs Binary Search
We've looked at a number of sorting algorithms which work over lists. Once we've sorted a list, we usually want to search it in some fashion.
There are fewer common search algorithms than sorting algorithms, and the trade-offs between them are a lot clearer. Let's take a look at by far the most common two types of search: linear search and binary search.
Linear Search
When working with lists, one of the first things we learn in programming is how to step through them. This is exactly how linear search works.
Take a list and a key. In this case, we're looking for 5.
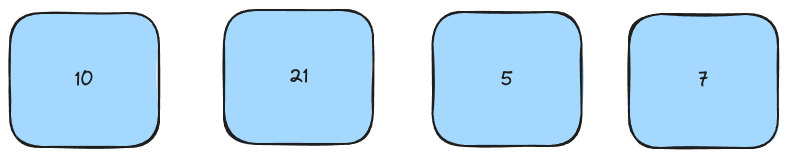
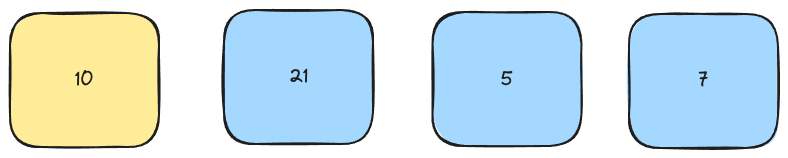
Now, check the first element in the list. Does it match the key?
As it doesn't, we continue through the list until we reach an element with the given key.
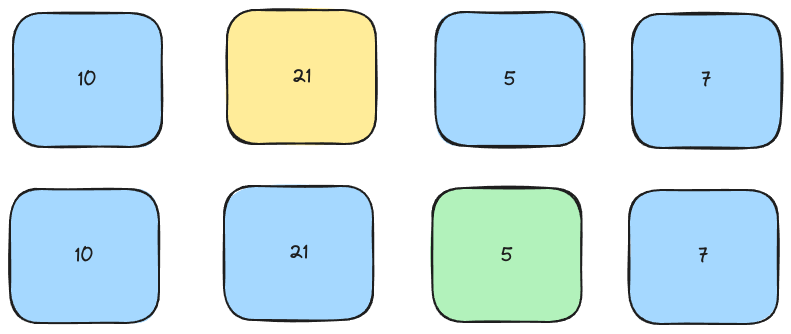
Linear search is an extremely simple algorithm which is available as a default method in most programming languages.
Depending on what exactly you want to do after you find an element matching a key, you will need to write a different method. This example checks whether a given key exists in a list of items.
def in_list(numbers: list[int], key[int]) -> bool:
for num in numbers:
if num == key: return True
return False
numbers = [x for x in range(1,101)]
print(in_list(numbers, 10))
print(in_list(numbers, 1000))
print(10 in numbers)
print(1000 in numbers)
What's the time complexity of a linear search? As we need to iterate through every item in a list to find our target, it's O(n).
Linear search cannot be optimised reliably in an unsorted list. This is common sense: in order to find an element in a list with no known order, we don't have a better way than checking every element until we find the one we want.
Exercise
While linear search is simple, generalising it over all data types is slightly more difficult.
Write an implementation of linear search which will find the element in a list which meets a given condition and return it. If the element is not found the function should return None.
from random import randint
# return the object with id 30 from the list, if it exists
objects = [ {"id": randint(1,50)} for x in range(1,51)]
# return the first string starting with the letter 'Z' from this list
words = [ "Apple", "Cherry", "Banana", "Zebra", "Airplane", "Bison" ]
Binary Search
Linear search is fine if we're working with unsorted lists. However, most of the time we're likely dealing with lists that have been sorted for us, and binary search can offer far better performance in this situation.
Binary search is similar to merge sort in its logic. Assume we have a sorted list of 7 elements, and we're looking for the element with key 12.
First, select a pivot at the center of your list:

If the pivot is greater than our target, we go to the left hand side of our list and ignore the right hand side. If the pivot is less than our target, we go to the right. In this case, we go left and select a new pivot.

We now repeat this process of selecting a pivot, checking it, and moving until we find the element we're looking for, or the partition we're looking at has no elements remaining.

Time Complexity of Binary Search
What's the time complexity of binary search? Let's look at this intuitively first, then with master theorem.
Intuitively, at each iteration of binary search we split our list in half (i.e. we perform n/2).
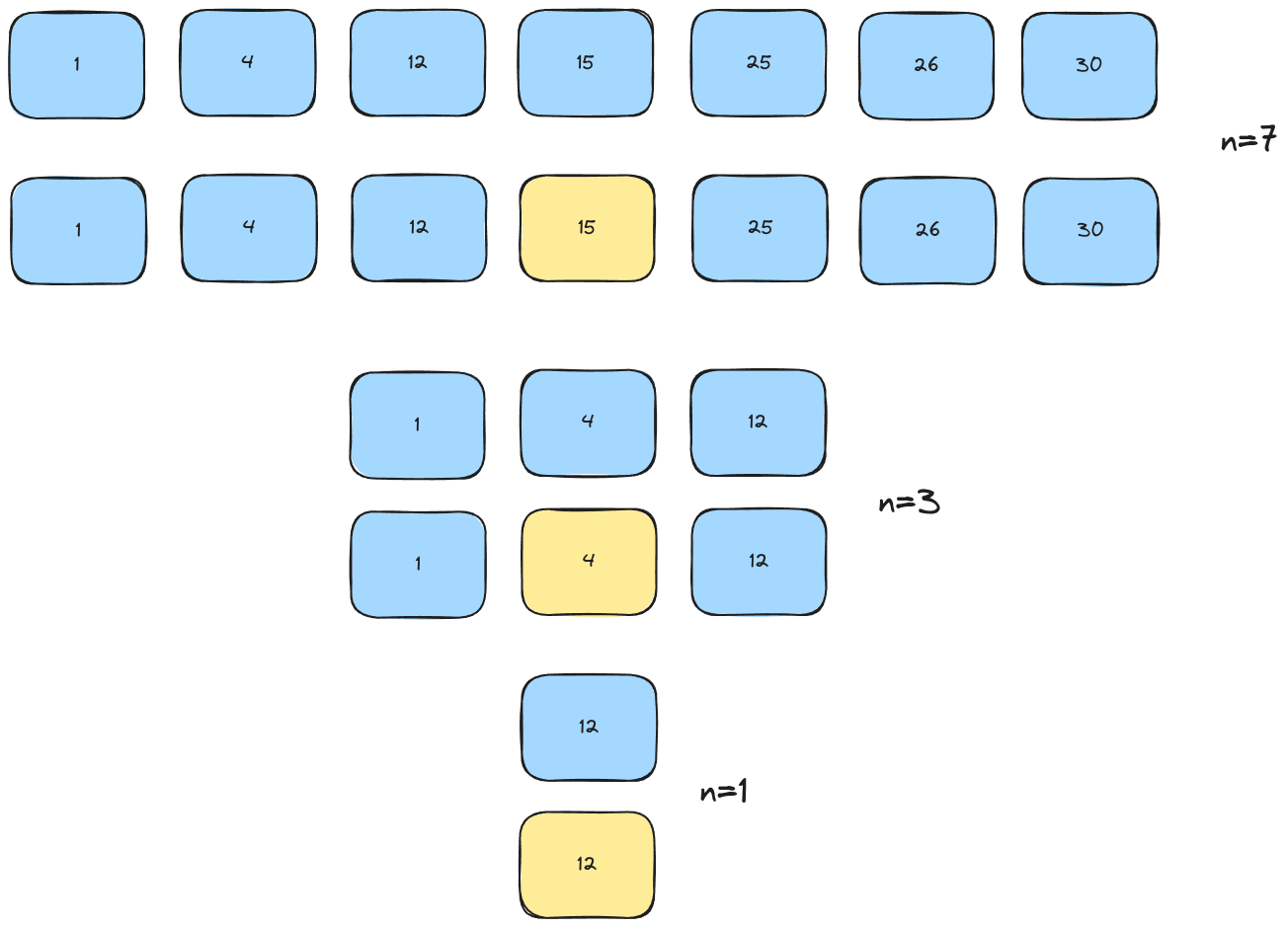
It takes 3 iterations, and each time we iterate we halve the number of items.
If we only had 4 items, it would take at most 2 iterations.
If we had 16 items, it would take at most 4 iterations.
If we had 32 items, it would take at most 5.
Where i is the number of iterations, n = 2^i.
Reversing this, so that we can arrive at the number of iterations (i.e. our time complexity) we get T(n) = O(log2(n)).
Now let's double-check our conclusion against the master theorem.
Let a be the number of times we recurse in an algorithm.
Let b be the amount we divide a list of length n by.
Let d be the time complexity of additional processing at a given level.
For an equation of the form T(n) = aT(n/b)+O(n^d):
a = b^d => T(n) = O((n^d)logb(n))
a < b^d => T(n) = O(n^d)
a > b^d => T(n) = aT(n/b)+O(n^d)
For binary search:
a = 1 as we only recurse once per partition
b = 2 as we split the list in half
d = 0 as our only processing is selecting a new pivot (constant time)
1 = 2^0, so this falls into case 1.
T(n) = O((n^d)logb(n))
T(n) = O((n^0)log2(n))
T(n) = O(1log2(n))
T(n) = O(log2(n))
So the master theorem supports the intuition that binary search has O(log2(n)) time complexity.
Knowledge Check
- Given which property of a list should we use linear search?
- Given which property of a list should we use binary search?
- How is binary search similar to merge sort?
- What's the time complexity of binary search? Why?
- When using linear search, we are able to benefit from substantial real-world performance boosts due to memory layout and CPU architecture making accessing contiguous memory locations very efficient. Given this, when do you think we should not use binary search over a list of sorted data?
- Given that binary search is a big improvement over linear search and we can arbitrarily increase the number of partitions to make a ternary, quad, etc. search, why do you think binary search is still preferred over searches with more partitions?
Exercise
Starting from the following list of 100 random numbers, write a function which returns the index of the number with the given key using binary search.
First, write a recursive implementation which directly slices the list.
Second, write an iterative implementation which does not slice the list, but instead maintains a pointer to the pivot. You will also need 1 or 2 more variables to track the size of partitions.
Which one is easier to write? Which one do you think is more efficient?
from random import randint
to_100 = [ randint(1,100) for x in range(100) ].sort()