Timsort and Other Compound Sorting Algorithms
You might have come away from some of the previous classes feeling confused about which sorting algorithm is best. Merge sort is stable and reasonably fast, but it's inefficient, doesn't adapt to data, and uses a lot of memory and disk space. Quicksort is quick, but it's unstable, more challenging to implement, and can fail to O(n^2). Insertion sort works well on small lists, but on larger lists it reverts to its usual runtime of O(n^2).
The truth is, there's no perfect sorting algorithm and each have their own benefits and drawbacks. However, we can overcome some of the drawbacks of a given algorithm by combining it with another one to form a compound sorting algorithm. One example of a compound sorting algorithm is Timsort, which we'll look at this time.
Timsort: One Compound Sorting Algorithm
Timsort is a sorting algorithm developed by Tim Peters in 2002. It's the default sort in Python, but performs well in any language.
Timsort was designed to provide a stable and fast sorting algorithm over a wide range of different data types. It's a combination of merge sort and insertion sort. Unlike merge sort, it adapts to cases where a list is already sorted. Unlike insertion sort, it performs well even in cases where a list is reversed, and rarely ends up with O(n^2) time in practice.
Unlike previous algorithms, we won't step through Timsort as having a high-level understanding of it will make it easier to visualise, and we should already be familiar with Merge Sort and Insertion Sort.
The main idea behind Timsort is runs of sorted elements. Let's take this list of 12 elements and split it into 4 sublists of 3 elements.
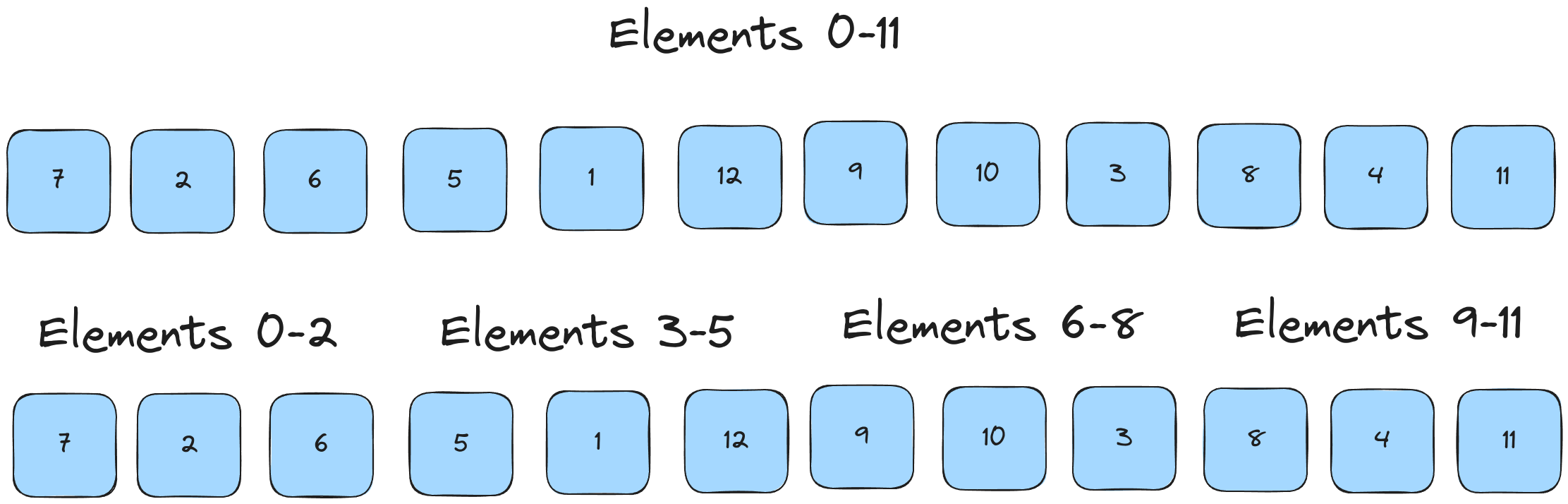
Now we run insertion sort across each sublist to make those elements sorted. Note that this is the same thing we achieve by recursion in Merge Sort.

We now merge adjacent sublists, using the merge algorithm from merge sort.

We continue merging sublists until the combined length of the sublists we're merging is equal to the length of the array.

And our list is sorted!
The basic logic of timsort is easy to understand, but we need to think a little bit about how we create and manage our sublists. Since insertion sort works best over short lists (less than 12 elements) and merge sort works best when the number of lists is a multiple of two, we need an algorithm that can guarantee those properties.
First, let's choose a threshold. This can be any number you like but it should probably be 12 or less. This is the maximum length of sublists.
Next, we'll divide our sublist length until it's smaller than our threshold. In order to make sure we always cover the list efficiently, we keep track of a remainder. If we don't do this, a list of 23 elements will end up as 3 lists of 11, 11, and 1 element rather than 2 lists of 12 and 11.
sublist_length = array_length
while sublist_length > THRESHOLD:
remainder = 0
if (sublist_length % 2) == 0:
remainder = 1
sublist_length = floor(sublist_length / 2) + remainder
Now we loop through our sublists and sort them. We clamp to the end of the parent array so that we don't raise an error if our sublist range is longer than the parent array.
for run_start in range
run_end = min(run_start + run_length, len(array))
insertion_sort(array,run_start,run_end)
Finally, we merge our sublists. We then double the length of the sublists we're working with and continue merging until we've merged the whole array.
merge_length = run_length
while merge_length < len(array):
for left in range(0, len(array), merge_length * 2):
mid = left + merge_length
right = min(len(array),mid + merge_length)
if mid < right:
merge(array,left,mid,right)
merge_length *= 2
Time and Space Analysis of Timsort
Timsort is simple to analyse if we're familiar with Merge Sort and Insertion Sort. We won't attempt a full mathematical analysis, but will instead consider a few cases.
The best case of Timsort comes about when there's only one list, it's shorter than our threshold for merging, and it's already sorted. In this case we never do any merging or splitting, and we drop through to insertion sort, which has O(n) time complexity over a sorted list.
The worst case of Timsort over one partition is O(n^2), like insertion sort. However, having a threshold for the length of sublists makes this a lot better than plain insertion sort. If we have a reversed list of 40 elements, split into 4 partitions then our time complexity is:
10 elements per sublist
Insertion sort has O(n^2) complexity
We need to run it over 4 partitions
10 ^ 2 = 100
100 * 4 = 400
Now we need to compare the lists, which takes 40 comparisons per level. There are two levels (10 and 20 elements), so 40 * 2 = 80 comparisons.
To sort a list like this therefore takes 480 comparisons. Contrast with the worst case of insertion sort by itself:
40 elements in the list
Insertion sort has O(n^2) complexity
40 ^ 2 = 1600
Therefore the real worst-case time complexity of timsort is:
Let s be the number of elements in each partition.
There are n/s partitions.
To merge we need to make nlogs(n) comparisons as s controls the number of elements at each level.
T(n) = (s^2) * n/s + nlogn
I.e. it's more than nlogn but less than n^2, but doesn't fit neatly into big O time complexity. Therefore we usually consider timsort's worst case time complexity to be O(nlogn).
By looking at the worst case and the best case, we can see that for most lists we will do some number of comparisons more than n but less than the worst case. The average case of Timsort is also O(nlogn).
While in theory Timsort's space complexity is O(n) like Merge Sort (because it needs a buffer array to merge lists), in practice it's often a lot less. This is because Timsort is not recursive and therefore doesn't make use of the call stack on the computer as heavily.
Other Compound Sorting Algorithms
Real-world software will often use some combination of sorting algorithms, like timsort does, to address the weaknesses of individual methods.
For example, it's common to combine quicksort with insertion sort when sorting large data sets for optimal performance. It would also be common to layer other optimisation techniques like indexing or maintaining a cache on top of the basic algorithms. These compound algorithms can become complex and in some cases might even be proprietary!
Another algorithm that uses a combination of methods is Block Sort. This uses a similar idea to timsort in combining merging and insertion sort, but is significantly more complex.
New sorting algorithms are being developed constantly for different use cases, and it's an open area of research! Timsort itself was developed to meet the need for a stable and performant algorithm for the Python standard library.
Review Questions
- What does Timsort add to insertion sort and merge sort in order to successfully combine them?
- Why do we want our sublists to be short in timsort?
- Why do we want an even number of sublists in timsort?
- What are the best and worst cases of timsort? How are these an improvement on merge sort and insertion sort?
- Is Timsort recursive? Could it be implemented recursively? Would we want to?
- Have you encountered any situations where you've had to combine basic algorithms to make a more useful, specialised algorithm? When was it?
Assignment
Implement Timsort over a list of random numbers. As the implementation of Timsort is quite lengthy but not that complicated, here's some framework code to get you started. It includes an implementation of insertion sort and of the merge function from mergesort. It also includes functions to check that (a) all of the values in the original list are still present in the sorted list and (b) that the list is sorted.
from random import randint
from math import floor, ceil
# theoretically, insertion sort is optimal for arrays of 12 or fewer elements
MAX_RUN_SIZE = 12
def insertion_sort(array, start, end):
# pythonic insertion sort implementation
for i in range(start, end):
k = i
while k >= start and array[k] > array[k+1]:
array[k], array[k+1] = array[k+1], array[k]
k -= 1
def merge(array, left, mid, right):
# allocate a list to keep the merged values
final = []
i = left
k = mid
while i < mid and k < right:
if array[i] < array[k]:
final.append(array[i])
i += 1
continue
final.append(array[k])
k += 1
while i < mid:
final.append(array[i])
i += 1
while k < right:
final.append(array[k])
k += 1
# finally, swap with the in-place array elements
for i in range(left, right):
array[i] = final[i - left]
def frequency(array):
freqs = {}
for el in array:
if el not in freqs:
freqs[el] = 0
freqs[el] += 1
return freqs
def compare_frequencies(a, b):
freq_a = frequency(a)
freq_b = frequency(b)
for k in freq_a:
if k not in freq_b: return False
if freq_a[k] != freq_b[k]: return False
for k in freq_b:
if k not in freq_a: return False
if freq_a[k] != freq_b[k]: return False
return True
def check_sorted(array):
prev = array[0]
for el in array:
if el < prev:
return False
prev = el
return True
def get_run_length(array):
pass
def timsort(array):
pass
def main():
randlist = [randint(1,50) for i in range(50)]
copy = randlist[:]
print(randlist)
timsort(randlist)
print(randlist)
print(f"Sorted: {check_sorted(randlist)}, Frequencies match: {compare_frequencies(randlist, copy)}")
if __name__ == "__main__":
main()
Further Reading
- Peter McIlroy's Optimistic sorting and information theoretic complexity
- Baeldung CS for pseudocode of Timsort used preparing this class.
- Github repo for my reference implementation of timsort.