Lexing On My Haters: How to Design a Programming Language I
Posted on Wed 12 July 2023 in general

Trying to build a complex program in Python is like trying to build a house out of jello. I love it, but while Python's delicious, flexible, and lacks the annoying quirks of most languages, this relaxed nature is a dire problem for complex projects. Python uses duck typing:
If it walks like a duck and quacks like a duck, it's a duck.
This means that you can write a program like:
my_set = {"a", "b", "c"}
my_dict= { "a": 1, "b": 2, "c": 3 }
for obj in (my_set, my_dict):
print(obj.get("a"))
Despite my_set and my_dict being different types, Python has no problem with this code. In complex programs where you want safe code, this means you need to annotate every type, and check objects' types before using them:
def print_this(x : str):
if not isinstance(x, str):
raise TypeError()
print(str)
This is both verbose and annoying. However, the alternatives are:
-
Trust future developers to write code conforming to your annotations.
-
Don't bother with types and let your program collapse under its own weight.
The first one sounds reasonable, but I don't trust myself to stick to type annotations, let alone other people. I could have switched to a strongly-typed language like C++ or Rust, which require you to declare all your types:
// If you call this with a non-string type, it will throw an error.
void printThis(string x) {
std::cout << x;
}
Thanks to Reddit user Human-Bathroom-2791 for catching a minor error in this code.
However, strongly-typed languages are usually more verbose and can be troublesome. One of the features that I love about Python is how productive I can be when writing it, due to its generous interpreter. I've also begun to prefer writing pure functions, which are functions which will always return the same output from a given input. This means that object-oriented languages like C++, which encourage using functions to manipulate state of objects, aren't a good fit for my current preferences.
Did I learn an existing functional language like Haskell or OCaml? Of course not. In my infinite wisdom, I decided the best choice was to create my own. I knew a bit about language design, but not enough to make my own language. I decided to change that.
Finite State Machines
To design a programming language, you need to understand state machines. I already knew the basics of state machines from experience and from high school computing. However, I hadn't used state machines for language parsing before, so I had to do some research. I asked Discord. Here's what I learned.
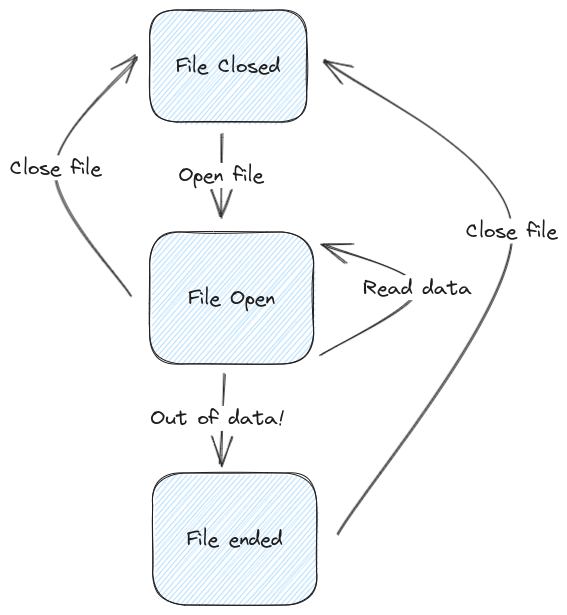
A finite state machine isn't a real machine - it's an abstract idea of a machine. A state machine consists of two concepts: a state, and a transition. For example, when you want to read a file on your computer, there are a few states it can be in:
-
Closed
-
Open and ready to read
-
End of file - no more reading is possible
It can transition between these three states in different ways:
-
When we open a file
-
When we close a file
-
When we reach the end of our file
-
When we successfully read some data from the file
We can draw out this state machine as a diagram, and can see which state transitions are invalid. For example, we can't go from a closed file to the end of file directly. We also can't continue to read from the end of a file. This is very helpful for modelling which inputs are valid and invalid in a given state.
I very quickly learned that parsing complex languages required a pushdown automaton, which is a special type of state machine. If you've looked into the history of computing before you might have heard of a Turing Machine, which is the most minimal machine which can perform any computable task. A pushdown automaton is closely related to a Turing Machine, but a little simpler.
A Turing Machine has a movable roll of tape with cells, each of which can contain a token such as 1 or > or burger. It also has a head which can read from or write to the tape. Every time the machine steps, it reads one symbol from the tape, and based on its current state can move the tape left or right, write a symbol, or stop. Turing machines are simple but can perform any computation, and are the model for the CPUs in computers.
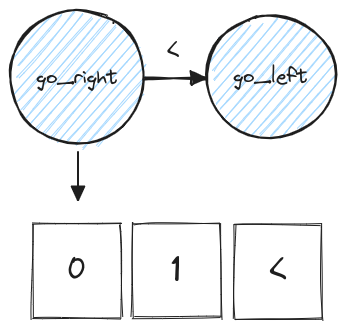
The Turing Machine in the go_right state will go right until it reaches < and reverses direction.
A pushdown automaton (PA) is similar to a Turing Machine, with two important differences. First, a PA cannot move or write to its tape: it just reads one symbol per step. Second, a PA has a stack which it can manipulate by pushing a symbol or popping a symbol from the top. While a PA is not as powerful as a Turing Machine, it's capable of parsing most common computer languages.
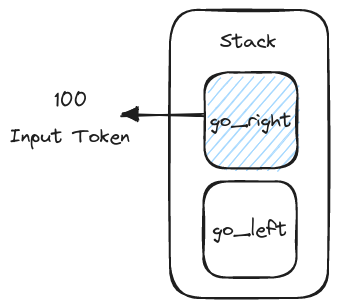
The current state of the pushdown automaton is go_right. Unlike a Turing Machine, it has no tape.
With my new knowledge of abstract machines, I felt ready to tackle a very basic language: math! I wanted to write math expressions like (10 + 10) * 4 - -10.5 and get the correct result as output.
My first step was writing a lexer, also known as a lexical or syntactic analyser. I flirted with writing a lexer generator, which is a piece of software which can generate any lexer, but decided not to after reading this:
The work of building a lexer is the same as designing a language.
Lexers take a string of characters and turn it into a series of tokens, which are more abstract symbols and make the job of a parser easier. For example, the string 10 + 10 might be lexed into three tokens: [number(10), ADD, number(10)].
Unfortunately math (technically: infix arithmetic) presents a few challenges for a language designer.
First, arithmetic expressions use parentheses: (1 + 2) * 2 should evaluate to 6. However, simple forms of parsing, including those supported by regular expressions, do not allow parentheses. Supporting nested expressions is a major motivation for developing parsers in the first place, and requires our pushdown automata.
A PA can push the current state to the stack when it reaches a ( symbol and pop it when it reaches the ) symbol, then continue with its previous state intact. In theory we could evaluate the whole expression using this method, but I just used it to output tokens.
The second challenge is distinguishing negative numbers from subtraction. Most numbers are simple: they're either a set of digits, or two sets of digits separated by a dot. But negative numbers are ambiguous: 1-1 can be interpreted as 1 + -1 (correct) or as 1, -1 (incorrect). My solution to this was hacky, but I later discovered that it's the usual approach for simple parsers. I set up my lexer to do the following when it discovered a - symbol:
-
Count how many
-symbols there are in a row. -
If there's an odd number and the next symbol is a valid expression, then turn the
-into+ -expr. -
If there's an even number, then:
-
If we're at the start of an expression, or after a
(, outputexpr. -
If we're not at the start of an expression, output
+ expr.
-
-
All
-symbols now meanNEGATE: i.e. doexpr * -1.
Based on these considerations, my lexer ended up with a set of rules for turning input into a set of tokens. These were:
-
Ignore any spaces.
-
If you see a digit
[0-9], keep adding digits to the current number until you reach something that's not a number, then add the number as a token. -
If you see a regular operator,
[+/*], make it into a token. -
If you see a
-sign, count how many there are in a row and make them intoNEGATEtokens. -
If you see
(, push the current state to the stack and return to the start of the inner expression. -
If you see
)or reach the end of the input, finalise the current token and output it, then pop the state on the stack or exit.
Let's step through this with a real example: (10 + 10) / -5. In addition to the stack and input required by a pushdown automaton, I added a tape to my lexer. This makes it easier to deal with long numbers and strings of - symbols. I'll ignore the steps which are skipping whitespace as they're uninteresting.
| Step | Input | Tape | Stack | Tokens |
|---|---|---|---|---|
| 0 | (10 + 10) / -5 |
[empty] |
[expect_expr] |
[empty] |
| 1 | 10 + 10 / -5 |
( |
[expect_expr, expect_operator] |
[empty] |
| 2 | 0 + 10) / -5 |
1 |
[parse_number, expect_operator] |
[(] |
| 3 | + 10) / -5 |
10 |
[parse_number, expect_operator] |
[(] |
| 4 | 10) / -5 |
+ |
[expect_expr, expect_operator] |
[(,10] |
| 5 | 0) / -5 |
1 |
[parse_number, expect_operator] |
[(,10,+] |
| 6 | ) / -5 |
10 |
[parse_number, expect_operator] |
[(,10,+] |
| 7 | / -5 |
) |
[expect_operator] |
[(,10,+,10,)] |
| 8 | -5 |
/ |
[expect_expr] |
[(,10,+,10,)] |
| 9 | 5 |
- |
[minus] |
[(,10,+,10,),/] |
| 10 | [empty] |
5 |
[parse_number] |
[(,10,+,10,),/,NEGATE,] |
| 11 | [empty] |
[empty] |
FINISHED |
[(,10,+,10,),/,NEGATE,5] |
With a small number of states and a pushdown automaton, we can turn a complex expression into useful tokens!
After writing the lexer I could turn any math expression into a set of tokens. However, they were still just a list and couldn't do any useful work. To go from a list of tokens to a program, I needed to write a parser.
The main reason for this is operator precedence. The result of 1 + 2 * 2 should be 5, because multiplication has higher precedence than addition. However, if we naively left-to-right like my lexer, then we will output 6 from this sum. We need something more complex: we need an operator-precedence parser. More on that next time.